1 聚类的基本概念
1.1 相似度 距离
聚类的对象是观测数据或者样本集合. 假设有 个样本, 个属性(feature), 将样本集合用矩阵 表示
矩阵的列表示样本, 行表示属性.
1.1.1 Minkowski 距离
在 K近邻法中我们定义了距离, 现在重新叙述一下记号:
给定样本集合 , . 定义 的Minkowski 距离为
- 时, 称为 Euclide 距离: ;
- 时, 称为 Manhattan 距离: ;
- 时, 称为 Chebyshev 距离: .
1.1.2 Mahalanobis 距离 (马氏距离)
给定样本集合 , 协方差矩阵 为 . 则 的Mahalanobis距离定义为
是 的第 列.
当 , 马氏距离就是欧式距离.
1.1.3 相关系数
的相关系数定义为 其中 .
1.1.4 夹角余弦
从向量的观点看, 的相似度还可以用夹角余弦
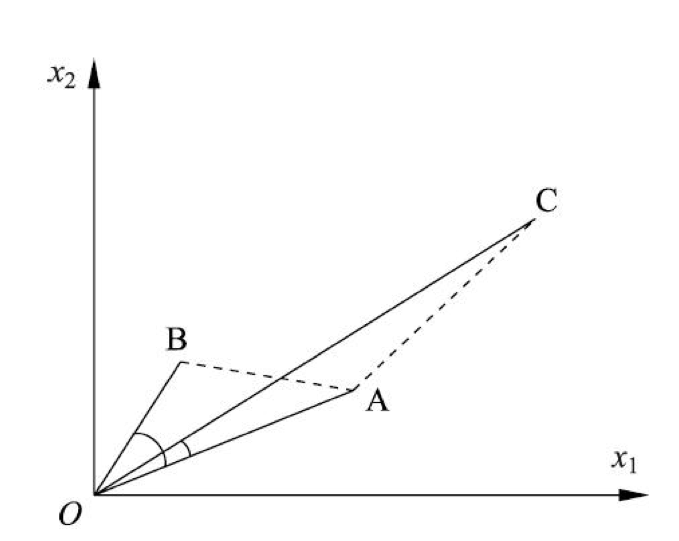
选择合适的距离或者相似度非常重要. 例如在上图中, 从距离来看 比 更相似; 从相关系数角度看, 比 更相似.
1.2 类或簇
类或簇是样本的子集. 硬聚类规定样本只能属于一个类, 软聚类则允许同时属于多个类. 本章考虑硬聚类.
用 表示类或簇, 用 表示类中的样本, 表示 中样本个数, 表示 距离.
给定正数 .
- , 则 是一个类.
- , 则 是一个类.
- , 则 是一个类.
- 给定正数 . , 满足 则 是一个类.
- 均值/中心 .
- 直径 .
- 样本散布矩阵 ;
样本协方差矩阵 .
1.3 类间距离
类 之间的距离 也称为连接(linkage). 设 . 用 表示两者的中心.
- 最短距离(single linkage) .
- 最长距离/完全连接(complete linkage) .
- 中心距离 .
- 平均距离 .
2 层次聚类
层次聚类假设类别间有层次结构(有点类似决策树), 分成
- 聚合(agglomerative)/自下而上 (bottom-up),
- 分裂(divisive)/自上而下 (top-down)
两种方法. 层次聚类属于硬聚类. 本文只考虑聚合聚类.
输入 个样本组成的样本集合; 样本间的距离
输出 样本集合的层次化聚类
- 计算 Euclide 距离 , 记为 .
- 构造 个类,每个类包含一个样本.
- 合并类间隔距离最小的两个类, 按其中的最短距离作为类间距离, 构造一个新类.
- 计算新类与当前各类的距离. 若类的个数为 , 终止计算, 否则会到 3.
复杂度是 . 事实上它构造了一个二叉树.
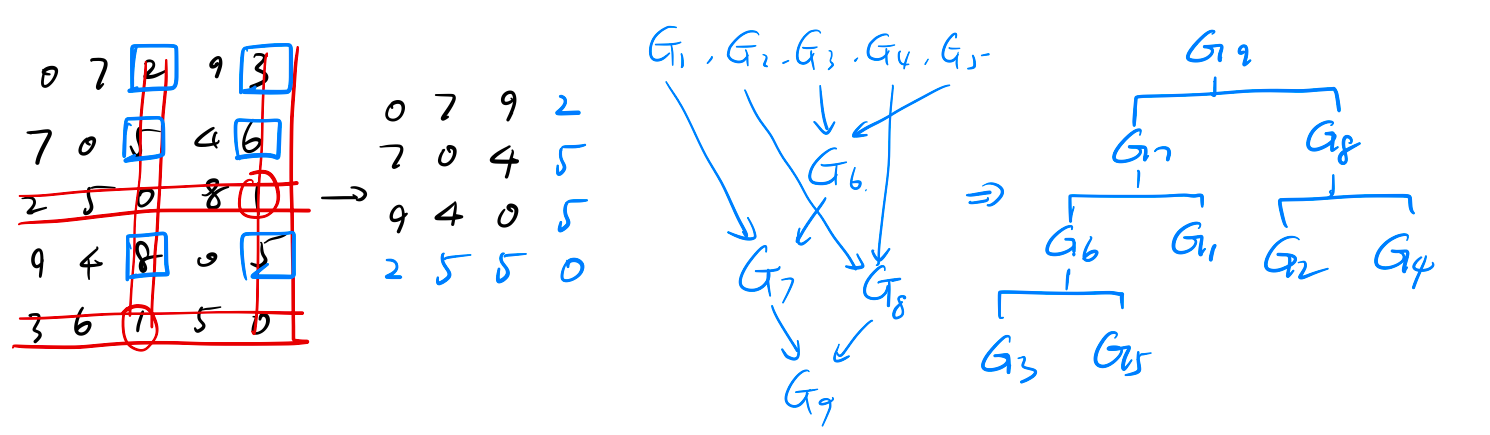
- 首先构造 .
- 看出 是距离最小的两个类, 将 合并成 . 此时写出新的距离矩阵 (按照 的顺序)
- 此时 最小, 因此合并 为 . 同理得到 (按 排序).
- 此时 最小, 合并为 .
- 最后 .
3 K 均值聚类 (K-Means)
3.1 模型与算法